Dans un environnement Solaris, j'ai dernièrement testé une connexion à une instance configurée en mode shared server. Pour information, l'instance appartient à un RAC 10g à 2 noeuds. Les clients sont écrits en PRO*C et se connectent à un dispatcher via un client Oracle 9i.
Les résultats sont les suivants:
- La durée de connexion est comprise en moyenne entre 20 à 25 ms.
- La durée de lecture d'une ligne d'une table de 20 colonnes ( lecture utilisant un index de la table ) est comprise entre 7 à 12 ms.
- La durée de lecture d'une ligne d'une table de 120 colonnes ( lecture utilisant un index de la table ) est comprise entre 11 à 16 ms.
Pour aller plus loin:
- Une description du mode shared server.
- Une description sur les connexions Oracle.
jeudi 13 mai 2010
dimanche 2 mai 2010
SPM ( SQL Plan Management )
Quelques liens:
- http://optimizermagic.blogspot.com/search/label/sql plan management
- http://www.oracle-base.com/articles/10g/AutomaticSQLTuning10g.php#sql_tuning_sets
- http://www.oracle-base.com/articles/11g/AutomaticSqlTuning_11gR1.php
Ce nouveau concept de la 11g permet de figer les plans d'exécution comme les stored outlines. De plus, il collecte pour une requête un meilleur plan d'exécution si l'optimiseur a trouvé un chemin d'accès plus performant pour récupérer les données. De cette manière, on est désormais à l'abri des changements brusques des plans d'exécution ( qui n'a pas connu cela sur une base de production ? ), tout en pouvant améliorer les temps d'exécution des requêtes de manière contrôlée.
- http://optimizermagic.blogspot.com/search/label/sql plan management
- http://www.oracle-base.com/articles/10g/AutomaticSQLTuning10g.php#sql_tuning_sets
- http://www.oracle-base.com/articles/11g/AutomaticSqlTuning_11gR1.php
Ce nouveau concept de la 11g permet de figer les plans d'exécution comme les stored outlines. De plus, il collecte pour une requête un meilleur plan d'exécution si l'optimiseur a trouvé un chemin d'accès plus performant pour récupérer les données. De cette manière, on est désormais à l'abri des changements brusques des plans d'exécution ( qui n'a pas connu cela sur une base de production ? ), tout en pouvant améliorer les temps d'exécution des requêtes de manière contrôlée.
mardi 30 mars 2010
Méthode de détection d'un problème ( partie 2 )
Si les vues associées aux wait events ne donnent aucun indice, on peut alors étudier les statistiques d'une session. Pour ce faire, on utilise les vues v$sesstat et v$statname. Pour information, une description succincte des statistiques est disponible dans une annexe du document de référence ( 11g: http://download.oracle.com/docs/cd/B28359_01/server.111/b28320/stats.htm#i29468 ).
L'outil de T.Poder, snapper, permet entre autres de visualiser les statistiques d'une session. Il est décrit à cette adresse: http://tech.e2sn.com/oracle-scripts-and-tools/session-snapper.
Par ailleurs, vous pouvez analyser un problème à partir des outils d'Oracle ( statspack ou awr ). Ce lien http://jonathanlewis.wordpress.com/statspack-examples/ vous aidera à interpréter ce type de rapport. L'outil ADDM permet également de recueillir quelques pistes d'optimisation.
Si tous ces outils ne vous permettent pas de résoudre votre problème, il reste alors à utiliser un outil comme dtrace ( http://hub.opensolaris.org/bin/view/Community+Group+dtrace/WebHome ), l'idée étant de descendre au niveau de la couche système pour détecter l'origine du problème.
L'outil de T.Poder, snapper, permet entre autres de visualiser les statistiques d'une session. Il est décrit à cette adresse: http://tech.e2sn.com/oracle-scripts-and-tools/session-snapper.
Par ailleurs, vous pouvez analyser un problème à partir des outils d'Oracle ( statspack ou awr ). Ce lien http://jonathanlewis.wordpress.com/statspack-examples/ vous aidera à interpréter ce type de rapport. L'outil ADDM permet également de recueillir quelques pistes d'optimisation.
Si tous ces outils ne vous permettent pas de résoudre votre problème, il reste alors à utiliser un outil comme dtrace ( http://hub.opensolaris.org/bin/view/Community+Group+dtrace/WebHome ), l'idée étant de descendre au niveau de la couche système pour détecter l'origine du problème.
dimanche 28 mars 2010
Cardinality feedback
Quelques liens:
- http://dioncho.wordpress.com/2009/12/17/trivial-research-on-the-cardinality-feedback-on-11gr2/
- http://wedostreams.blogspot.com/2009/12/hidden-undocumented-and-adaptive-cursor.html
- http://jonathanlewis.wordpress.com/2009/12/16/adaptive-optimisation/
En se connectant en tant que SYS, vous pouvez visualiser les caractéristiques d'un paramètre caché de la manière suivante:
select ksppinm as param,
y.ksppstvl as ses_val,
z.ksppstvl as inst_val,
decode(bitand(ksppiflg/256,1),1,'TRUE','FALSE') as ses_modif,
decode(bitand(ksppiflg/65536,3),1, 'IMMEDIATE',2,'DEFERRED', 3,'IMMEDIATE','FALSE') as system_modif,
ksppdesc as descr
from x$ksppi x, x$ksppcv y, x$ksppsv z
where x.indx = y.indx
and x.indx = z.indx
and ksppinm like '\_%' escape '\'
order by ksppinm;
- http://dioncho.wordpress.com/2009/12/17/trivial-research-on-the-cardinality-feedback-on-11gr2/
- http://wedostreams.blogspot.com/2009/12/hidden-undocumented-and-adaptive-cursor.html
- http://jonathanlewis.wordpress.com/2009/12/16/adaptive-optimisation/
En se connectant en tant que SYS, vous pouvez visualiser les caractéristiques d'un paramètre caché de la manière suivante:
select ksppinm as param,
y.ksppstvl as ses_val,
z.ksppstvl as inst_val,
decode(bitand(ksppiflg/256,1),1,'TRUE','FALSE') as ses_modif,
decode(bitand(ksppiflg/65536,3),1, 'IMMEDIATE',2,'DEFERRED', 3,'IMMEDIATE','FALSE') as system_modif,
ksppdesc as descr
from x$ksppi x, x$ksppcv y, x$ksppsv z
where x.indx = y.indx
and x.indx = z.indx
and ksppinm like '\_%' escape '\'
order by ksppinm;
dimanche 14 février 2010
Extended cursor sharing
Jusqu'à la version 11g, le mécanisme dit de peek bind variable posait parfois des problèmes lorsque la sélectivité des différentes valeurs des bind variables était différente. Désormais, le mécanisme dit d'extended cursor sharing permet de corriger ce défaut après quelques exécutions.
Pour illustrer ce nouveau mécanisme, on crée une nouvelle table:
create table adapt_curs_share (
idf number,
date_ins date,
chaine varchar2(80),
nombre number not null )
tablespace 'nom_tablespace';
create sequence seq_adapt_curs_share
increment by 1
start with 1
;
create index idx_adapt_curs_share_nombre on adapt_curs_share(nombre) tablespace 'nom_tablespace';
On l'alimente de la manière suivante:
begin
for i in 1..100000
loop
insert into adapt_curs_share
(idf, date_ins, chaine, nombre)
values
(seq_adapt_curs_share.nextval, sysdate, dbms_random.string('P', 80), abs(mod(dbms_random.random(),1000 )));
end loop;
commit;
end;
On calcule les statistiques et on nettoie le shared pool :
dbms_stats.gather_table_stats(
ownname => 'schéma',
tabname => 'adapt_curs_share',
method_opt=>'for all columns size 1',
cascade => true);
alter system flush shared pool;
Avant d'ouvrir la session sous DOS, il est souhaitable de positionner le bon jeu de caractères:

On positionne le niveau le plus élevé pour les statistiques afin de recueillir plus d'informations au niveau des plans d'exécution:
alter session set statistics_level = all;
Une fois la configuration mise en place, on exécute sous sqlplus les instructions suivantes:
variable n number
exec :n := 999
select count(idf) from adapt_curs_share where nombre < :n; ( résultat: 99893 )
exec :n :=3
select count(idf) from adapt_curs_share where nombre < :n; ( résultat: 308 )
Le plan d'exécution de la requête est le suivant:
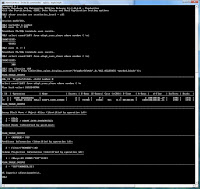
Le contenu de la bind variable est 999, la valeur utilisée par la première exécution de la requête. Etant donné la faible sélectivité de la requête, un access full est effectué sur la table adapt_curs_share. La deuxième requête, bien que très sélective, va utiliser le même plan d'exécution, d'où l'idée d'améliorer le mécanisme de peek bind variable via le concept d'extended cursor sharing.
Dans la vue v$sql, les colonnes is_bind_sensitive ( utilisation du peek bind variable ), is_bind_aware ( utilisation de l'extended cursor sharing ) et is_shareable ( curseur partagé ou non ) donnent pour ce curseur le triplet (Y, N, Y).
Suite à ces deux premières exécutions, on effectue les opérations suivantes:
exec :n :=3
select count(idf) from adapt_curs_share where nombre < :n;
exec :n :=999
select count(idf) from adapt_curs_share where nombre < :n;
Pour le curseur 9fyq0vr5fh4dn, on observe désormais dans la vue v$sql trois fils au lieu d'un. Le fils 0 a exécuté les deux premières requêtes. Il utilise le mécanisme du peek bind variable, mais pas celui de l'extended cursor sharing et il n'est plus partageable.
Le fils 1 a exécuté la troisième requête ( bind variable = 3 ). Il utilise le peek bind variable, l'extended cursor sharing et il est partageable. Son plan d'exécution est le suivant;

Le fils 2 a exécuté la quatrième requête ( bind variable = 999 ). Il utilise le peek bind variable, l'extended cursor sharing et il est partageable. Son plan d'exécution est le suivant;

Si on exécute de nouveau la requête avec les deux valeurs 3 et 999, seuls les fils 1 et 2 sont utilisés.
Pour aller plus loin sur ce nouveau concept lié à la 11g, vous pouvez aussi consulter les vues v$sql_cs_statistics, v$sql_cs_selectivity et v$sql_cs_histogram.
Pour illustrer ce nouveau mécanisme, on crée une nouvelle table:
create table adapt_curs_share (
idf number,
date_ins date,
chaine varchar2(80),
nombre number not null )
tablespace 'nom_tablespace'
increment by 1
start with 1
;
On l'alimente de la manière suivante:
begin
for i in 1..100000
loop
insert into adapt_curs_share
(idf, date_ins, chaine, nombre)
values
(seq_adapt_curs_share.nextval, sysdate, dbms_random.string('P', 80), abs(mod(dbms_random.random(),1000 )));
end loop;
commit;
end;
On calcule les statistiques et on nettoie le shared pool :
dbms_stats.gather_table_stats(
ownname => 'schéma',
tabname => 'adapt_curs_share',
method_opt=>'for all columns size 1',
cascade => true);
alter system flush shared pool;
Avant d'ouvrir la session sous DOS, il est souhaitable de positionner le bon jeu de caractères:

On positionne le niveau le plus élevé pour les statistiques afin de recueillir plus d'informations au niveau des plans d'exécution:
alter session set statistics_level = all;
Une fois la configuration mise en place, on exécute sous sqlplus les instructions suivantes:
variable n number
exec :n := 999
select count(idf) from adapt_curs_share where nombre < :n; ( résultat: 99893 )
exec :n :=3
select count(idf) from adapt_curs_share where nombre < :n; ( résultat: 308 )
Le plan d'exécution de la requête est le suivant:

Le contenu de la bind variable est 999, la valeur utilisée par la première exécution de la requête. Etant donné la faible sélectivité de la requête, un access full est effectué sur la table adapt_curs_share. La deuxième requête, bien que très sélective, va utiliser le même plan d'exécution, d'où l'idée d'améliorer le mécanisme de peek bind variable via le concept d'extended cursor sharing.
Dans la vue v$sql, les colonnes is_bind_sensitive ( utilisation du peek bind variable ), is_bind_aware ( utilisation de l'extended cursor sharing ) et is_shareable ( curseur partagé ou non ) donnent pour ce curseur le triplet (Y, N, Y).
Suite à ces deux premières exécutions, on effectue les opérations suivantes:
exec :n :=3
select count(idf) from adapt_curs_share where nombre < :n;
exec :n :=999
select count(idf) from adapt_curs_share where nombre < :n;
Pour le curseur 9fyq0vr5fh4dn, on observe désormais dans la vue v$sql trois fils au lieu d'un. Le fils 0 a exécuté les deux premières requêtes. Il utilise le mécanisme du peek bind variable, mais pas celui de l'extended cursor sharing et il n'est plus partageable.
Le fils 1 a exécuté la troisième requête ( bind variable = 3 ). Il utilise le peek bind variable, l'extended cursor sharing et il est partageable. Son plan d'exécution est le suivant;

Le fils 2 a exécuté la quatrième requête ( bind variable = 999 ). Il utilise le peek bind variable, l'extended cursor sharing et il est partageable. Son plan d'exécution est le suivant;

Si on exécute de nouveau la requête avec les deux valeurs 3 et 999, seuls les fils 1 et 2 sont utilisés.
Pour aller plus loin sur ce nouveau concept lié à la 11g, vous pouvez aussi consulter les vues v$sql_cs_statistics, v$sql_cs_selectivity et v$sql_cs_histogram.
jeudi 28 janvier 2010
Méthode de détection d'un problème ( partie 1 )
Sur ce sujet, je vous conseille de consulter les différents messages de Tanel Poder et James Morle:
- http://jamesmorle.wordpress.com/2009/11/09/the-oracle-wait-interface-is-useless-sometimes-pt/
- http://blog.tanelpoder.com/2010/01/15/beyond-oracle-wait-interface-part-2/
- http://jamesmorle.wordpress.com/2010/01/18/the-oracle-wait-interface-is-useless-sometimes-part-3a/
- http://jamesmorle.wordpress.com/2010/02/16/the-oracle-wait-interface-is-useless-sometimes-part-3b/
Pour détecter un problème dans une instance Oracle, on peut commencer par utiliser l' interface des wait events.
Un wait event représente une attente d'un processus utilisateur ( session ) ou de l'instance ( PMON, SMON ... ). Elle peut être liée à l'accès à une ressource ( données du cache, verrous ... ) . Par exemple, une session qui a besoin d'un bloc d'index absent dans la SGA effectue une demande de lecture au système, puis attend la réception du bloc. Ce temps d'attente est un type de wait event, en l'occurence le wait event db file sequential read.
Les deux vues utiles sont v$session_wait ( niveau session ) et v$system_event ( niveau instance ). Le script sw.sql de T.Poder donne un exemple d'utilisation de la vue v$session_wait.
Une description détaillée des wait events est disponible à cette adresse: http://sites.google.com/site/embtdbo/wait-event-documentation.
L'event trace de type 10046 permet aussi de récupérer les wait events. Au niveau d'une session, on l'active de la manière suivante:
- alter session set timed_statistics = true; -- Activation des Extended SQL Trace
- alter session set max_dump_file_size = unlimited;
- alter session set events '10046 trace name context forever, level 8';
- alter session set events '10046 trace name context off';
Pour tracer une session autre que la sienne, on peut utiliser la méthode set_ev du package dbms_system ou l'outil de debug d'Oracle, oradebug.
On peut récupérer les traces dans le répertoire indiqué par le paramètre d'initialisation USER_DUMP_DEST. Le suffixe des fichiers trace est trc ou TRC. On peut faciliter l'identification du fichier trace via cette commande: alter session set tracefile_identifier = 'MonFichierTrace'. L'utilitaire tkprof permet de mettre en forme les fichiers trace.
Le chapitre 5 du livre de Cary Millsap, Optimizing Oracle Performance, constitue une introduction intéressante pour la compréhension des traces SQL étendues. Une mise à jour est disponible à cette adresse: http://method-r.com/downloads/doc_details/72-mastering-performance-with-extended-sql-trace.
Si nécessaire, l'analyse du problème peut être étendue à la couche système. Pour commencer, on utilise la commande vmstat pour avoir une vision générale du système ( CPU, mémoire virtuelle ). Puis, on peut étudier plus en détail les processus ou threads ( top, topas, prstat ), la CPU ( mpstat ), les interruptions (intrstat ), les appels système ( truss, strace ).
- http://jamesmorle.wordpress.com/2009/11/09/the-oracle-wait-interface-is-useless-sometimes-pt/
- http://blog.tanelpoder.com/2010/01/15/beyond-oracle-wait-interface-part-2/
- http://jamesmorle.wordpress.com/2010/01/18/the-oracle-wait-interface-is-useless-sometimes-part-3a/
- http://jamesmorle.wordpress.com/2010/02/16/the-oracle-wait-interface-is-useless-sometimes-part-3b/
Pour détecter un problème dans une instance Oracle, on peut commencer par utiliser l' interface des wait events.
Un wait event représente une attente d'un processus utilisateur ( session ) ou de l'instance ( PMON, SMON ... ). Elle peut être liée à l'accès à une ressource ( données du cache, verrous ... ) . Par exemple, une session qui a besoin d'un bloc d'index absent dans la SGA effectue une demande de lecture au système, puis attend la réception du bloc. Ce temps d'attente est un type de wait event, en l'occurence le wait event db file sequential read.
Les deux vues utiles sont v$session_wait ( niveau session ) et v$system_event ( niveau instance ). Le script sw.sql de T.Poder donne un exemple d'utilisation de la vue v$session_wait.
Une description détaillée des wait events est disponible à cette adresse: http://sites.google.com/site/embtdbo/wait-event-documentation.
L'event trace de type 10046 permet aussi de récupérer les wait events. Au niveau d'une session, on l'active de la manière suivante:
- alter session set timed_statistics = true; -- Activation des Extended SQL Trace
- alter session set max_dump_file_size = unlimited;
- alter session set events '10046 trace name context forever, level 8';
- alter session set events '10046 trace name context off';
Pour tracer une session autre que la sienne, on peut utiliser la méthode set_ev du package dbms_system ou l'outil de debug d'Oracle, oradebug.
On peut récupérer les traces dans le répertoire indiqué par le paramètre d'initialisation USER_DUMP_DEST. Le suffixe des fichiers trace est trc ou TRC. On peut faciliter l'identification du fichier trace via cette commande: alter session set tracefile_identifier = 'MonFichierTrace'. L'utilitaire tkprof permet de mettre en forme les fichiers trace.
Le chapitre 5 du livre de Cary Millsap, Optimizing Oracle Performance, constitue une introduction intéressante pour la compréhension des traces SQL étendues. Une mise à jour est disponible à cette adresse: http://method-r.com/downloads/doc_details/72-mastering-performance-with-extended-sql-trace.
Si nécessaire, l'analyse du problème peut être étendue à la couche système. Pour commencer, on utilise la commande vmstat pour avoir une vision générale du système ( CPU, mémoire virtuelle ). Puis, on peut étudier plus en détail les processus ou threads ( top, topas, prstat ), la CPU ( mpstat ), les interruptions (intrstat ), les appels système ( truss, strace ).
mardi 12 janvier 2010
Plan d'exécution ( partie 2 )
Une fois une requête exécutée, vous pouvez visualiser son plan d'exécution contenu dans la library cache, une partie du shared pool ( SGA ) via la commande suivante: select * from table(dbms_xplan.display_cursor('id_requete', 0));
L'identifiant de requête ( sql_id ) est une chaîne de caractères ( exemple: dqbzw72kjmvhb ). On peut le retrouver à l'aide de la vue v$sql ( colonnes sql_text et sql_fulltext pour une recherche sur le texte de la requête, colonnes last_load_time et last_active_time pour la première ou dernière exécution ).
Pour utiliser le package dbms_xplan, il faut pouvoir lire les vues du catalogue. Pour ce faire, l'instruction est la suivante: grant select_catalog_role to'utilisateur'; .
Pour information, la fonction display_cursor est une encapsulation des vues v$sql_plan et v$sql_plan_statistics_all.
L'identifiant de requête ( sql_id ) est une chaîne de caractères ( exemple: dqbzw72kjmvhb ). On peut le retrouver à l'aide de la vue v$sql ( colonnes sql_text et sql_fulltext pour une recherche sur le texte de la requête, colonnes last_load_time et last_active_time pour la première ou dernière exécution ).
Pour utiliser le package dbms_xplan, il faut pouvoir lire les vues du catalogue. Pour ce faire, l'instruction est la suivante: grant select_catalog_role to
Pour information, la fonction display_cursor est une encapsulation des vues v$sql_plan et v$sql_plan_statistics_all.
Inscription à :
Articles (Atom)

